
Workin Out
devlog[08] - making a LoRA on the cheap
Now that I've shipped the 2nd milestone of Workin' Out nearly on the schedule I intended, I'm going to take pause to review the project and see how close I've come to achieving the project goals.
Quick warning - this post contains NSFW content.
The first major shortcoming of the effort was my disappointment with how the Gwen character was rendered image to image - I've already written a devlog on redoing all the major images from milestone 1 while getting things ready for milestone 2 (Workin' Out - devlog[03]). This post will be a longer explanation of why this was important to correct and, while not providing all the technical steps and tools needed to set up and create the LoRA (there are much better resources available on the web) I'll discuss the process and decisions taken along the way as it applied to the Workin' Out project.
Gwendolyn is the main character
First and obviously - why is Gwen so important? Because she's the main character! Even though the story is told and narrated from the perspective of Roland, it's really Gwen's story. She's the protagonist and she appears in almost all the graphical elements. So, it was a huge oversight on my part to even begin trying to create the story before completely locking down the Gwen concept.
Second - this project has been a test to figure out if Stable Diffusion can work in the context of producing the content for a VN... and how much up front time is needed. SD can generate a similar looking character given a base prompt - but there's a lot of inter-picture variation (by design) that makes a native SD solution not appropriate to generate all the visual content of a VN without some guidelines... YMMV, depending on how far your character strays from the native SD concept. SD does a reasonable job with a pretty basic conceptualization:
draw a pretty, athletic, young woman with red hair wearing a yellow sundress:

(super basic, totally wrong, but repeatable)
But if your character has more extreme (non average) characteristics, it gets harder to maintain consistency image to image:
draw a pretty, slight:1.6, petite:2.0, skinny:1.8, [athletic], young woman with ginger low twin braids wearing a yellow sundress:

(the added classifiers bring the image closer to what she needs to look like, at the expense of render time due to the complexity of the tokens... about 4x longer to render. Becoming less repeatable, hence adding the strengths (:1.6) and [de-emphasis] to the prompt... and her face will differ picture to picture)
Enter the LoRA
LoRA (Low-Rank Adaptations) are smaller files (anywhere from 1MB ~ 200MB) that you combine with an existing Stable Diffusion checkpoint models to introduce new concepts to your models, so that your model can generate these concepts.
(One example, a pretty good guide to get started: https://aituts.com/stable-diffusion-lora/)
I've experimented with using LoRA's before to help with character consistency, but my earlier attempts used between 20 to 50 different source images, which can be very time consuming to assemble, catalog, and annotate. I have built a successful model with as few as 5 images, so for this project I targeted the lower end of the range.
In order to explain more of the source image selection I also need to explain a bit about how I've been generating the Gwen content for Workin' Out. Specifically how I take a single image and use SD inpainting to create multiple expressions - it's a very similar process to how a normal artist would take their original character drawn with a neutral expression:

and then block out and replace the face - except in SD I mask her face and instruct the inpaint function to change the expression from neutral to smiling:

And - presto: you get a new image with the new expression you're looking for. Very useful when creating a VN.
Even more useful when You're assembling resources for creating a LoRA - because the images are highly consistent, you're reenforcing the body traits in the model, and the training uses the multiple expressions to learn the face across a range of expressions. So, I had a few of these ready to go from the first attempt of creating Workin' Out. Some were the above image, medium closeup with good focus on her face. Others were full length standing with a little less detail on the face... but overall a good starting point.

Next I needed to add more body references to fill out the model training... but I didn't have anything in my current working images directory that fit the bill. So, on to the next trick that traditional illustrators have - creating a character sheet.
There are several LoRA's already available that help guide creation of character sheets (front, back and side views), using that and a lot of prompt guidance I was able to put together a sheet that wasn't perfect... but would be good enough to start the training with. The advantage of using this character sheet method is you get very good character consistency between the different views - much better than a typical SD renders of separate prompts for a character front, back and side.
That said, I've found that it's better to split the single multi-view character sheet up into individual images in the training set, so a little work in MS Paint and the single picture got trimmed into three which were added to the training set:
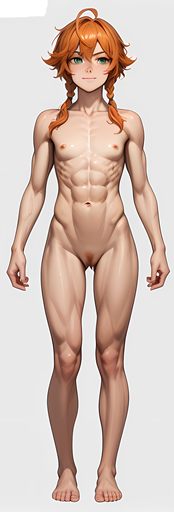 |  |  |
| front | back | side |
Not perfect mind you - the face is low resolution and a bit mannish, and muscles are a little overdeveloped for what Gwen actually should look like, but for a training set it's good enough - the trained LoRA isn't going to reproduce the image with perfect fidelity... it's more a guide of the pattern the character should follow - and these will be blended with the other body images in the working set. So in this instance, being that Gwen is a petite, athletic woman with small features this was close enough.
Lastly, I had a few extra images that I really liked for different reasons that met the criteria of being close enough to the above images to not make the model too broad; need to keep any detailed face views close to consistent since that's the real focus of this LoRA:
 |
| Here her face and expression are prefect, and her body proportions are exactly right. |
 |
| Face isn't correct, but muscles of her arms, her breasts, and ass are lovely. |
 |
| Again her face isn't perfect, but her proportions, abs, serratus anterior, breasts and hips are perfect. |
 |
| This picture was a happy accident early in the pre-visualization process that will re-appear in the last chapters. I've always kept it around as one of the key Gwen inspiration pictures. |
And there you go - that's about the full set of input images that were used to bake the LoRA. A total of 14 images were used. They all had to be annotated, again- there are tools and tutorials available to help this process (Booru Dataset Tag Manager is what I used) - the key is describing to the model trainer what it's seeing and what details should included vs what should be ignored.
Taking the Gwen in a black dress image from above, the annotation is (where workingwen is the constant LoRA identifier) the following tags were kept in the annotation file:
workingwen, anime - style image of a woman in a black dress sitting on a bed, arm support, bangs, bare shoulders, black choker, choker, collarbone, crossdressing, dress, eyelashes, gradient, gradient background, lips, looking at viewer, nipples, parted bangs, solo, rating:questionable
And the nude Gwen reclining on the bed was:
workingwen, anime - style image of a woman with red hair laying on a bed, bed, bed sheet, blush, braid, braided ponytail, breasts, female pubic hair, freckles, hair over shoulder, long hair, looking at viewer, lying, navel, night, night sky, nipples, nude, on back, on bed, pillow, pubic hair, pussy, skyscraper, small breasts, solo, spread legs, star \(sky\), starry sky, erect nipples, twin braids, uncensored, rating:explicit
Bake those images and annotations through the model engine for about 1500 iterations and out pops a 90 MB LoRA (pretty small, actually...) that reliably generates the Gwen character with her main traits intact. However, I've found it always helps to reenforce the most important features in the prompt provided to SD as a way to make sure the token processor/renderer explicitly shows them. Add a few additional post-processing LoRA's (detail, lighting) and you have the start of the image creation pipeline I've been using for Workin' Out:
draw workingwen, beautiful, petite:2.0, slight:1.8, (small) round breasts, [muscular], tiny waist, slender arms, [abs], athletic, freckles, shoulder length ginger unkempt tangled hair, low twintails, twin braids, BREAK. gray-green iris:2.0, mascara, heavy eyeliner, makeup:1.2, BREAK. standing, wearing a yellow sundress

Overall, the process I described above took about two days of resource assembly, annotation and processing, but I really wish I'd taken these steps before starting generating the content for chapter 1 - in net it would have saved me a bunch of time.
I'm curious (and congrats if you've read this far, sorry for being so long winded) - Is anyone else working with Stable Diffusion for their project? Have you tried this approach? Did I miss clever shortcuts to build a LoRA faster or with higher fidelity?
Regards,
-Insomniac
Leave a comment
Log in with itch.io to leave a comment.