
Workin Out
devlog[02] - ControlNet or Crutch
Over the past week I have nearly completed the script/dialogue writing for the second milestone, including some much needed edits to the first person action dialogue (it was terribly inconsistent). All that leaves is the hard part... the generating of the image elements. I expect a few weeks to get the needed content to an acceptable state. So, while the laptop churns out pictures, I figured I'd update anyone who's interested on the how.
For this project I have been using Stable Diffusion (SD) with the Automatic1111 UI. With SD you can easily create images from the text prompts you supply it... but, getting stable characters is a challenge... that I'm forgoing for this project. I accept there will be some drift from set image to image. I'm trying to use some other tricks to minimize that, rather than invest the time and effort in generating LoRA's to use for the main characters (that will probably be it's own discussion... since at the end of the day... the perfectionist in me will make me go that route).
The power of SD is the ability to rapidly generate image concepts on commodity grade hardware. For this project, I'm generating the images on a Laptop RTX 4070, and can draft between 4 and 10 low resolution images in less than an fifteen minutes. From there, it's an iterative process of selecting the starting image that most closely maintains the look of the character while fulfilling the image requirement and running it through multiple cycles of in-painting to make small corrections, fixes, add detail, upscale and remove any backgrounds.
But that only works when the text prompt supplied is correctly interpreted by SD into an image that captures the intent. When that fails, I'm confronted by the choice of changing the visual element (and breaking the story line as I've envisioned it), or going to extreme measures. For one of the images required at the end of chapter two, I was unable to get the following prompt (segment) to be correctly interpreted by SD:
subject is standing in front of viewer, POV is from above and looking down, close up, reaching for viewer, hugging viewer
You might be mistaken in thinking that is an easy enough concept for SD to interpret... I did. And I was wrong. Since the overall prompt is actually pretty complicated, there is a lot of additional character description to define what Gwendolyn (the subject) looks like, her mood, what she's wearing, etc., the SD token interpreter keeps missing the reaching out to the viewer part (regardless of how much emphasis I added to the tokens) and delivers pictures (so many pictures... more than 25 in 5 batches). The result that look like this:

A pretty picture, sure... and consistent enough with the character concept that I could use it... if the pose was correct. So, what to do...
ControlNET is a module that allows the SD model to be well... controlled - or more correctly: influenced. It's still doing the image generation process via the token processor and stability iterative process, but ControlNET can override the prompt/tokenizer to influence the what the character is doing.
To enable this, first I generate a marionette image of what I need my character doing. The website PoseMy.art is pretty useful in generating quick poses/images. Using one of the stock models I roughly aligned the upper body and arms to the needed pose and positioned the camera where I wanted it, then exported the image as a simple png that looks like:

Not a lot of detail is needed, since this line drawing is going to be interpreted by ControlNET into a simple character model for the SD interpreter. Once the interpreter pre-processes that image you are presented with a wire representation of the model:
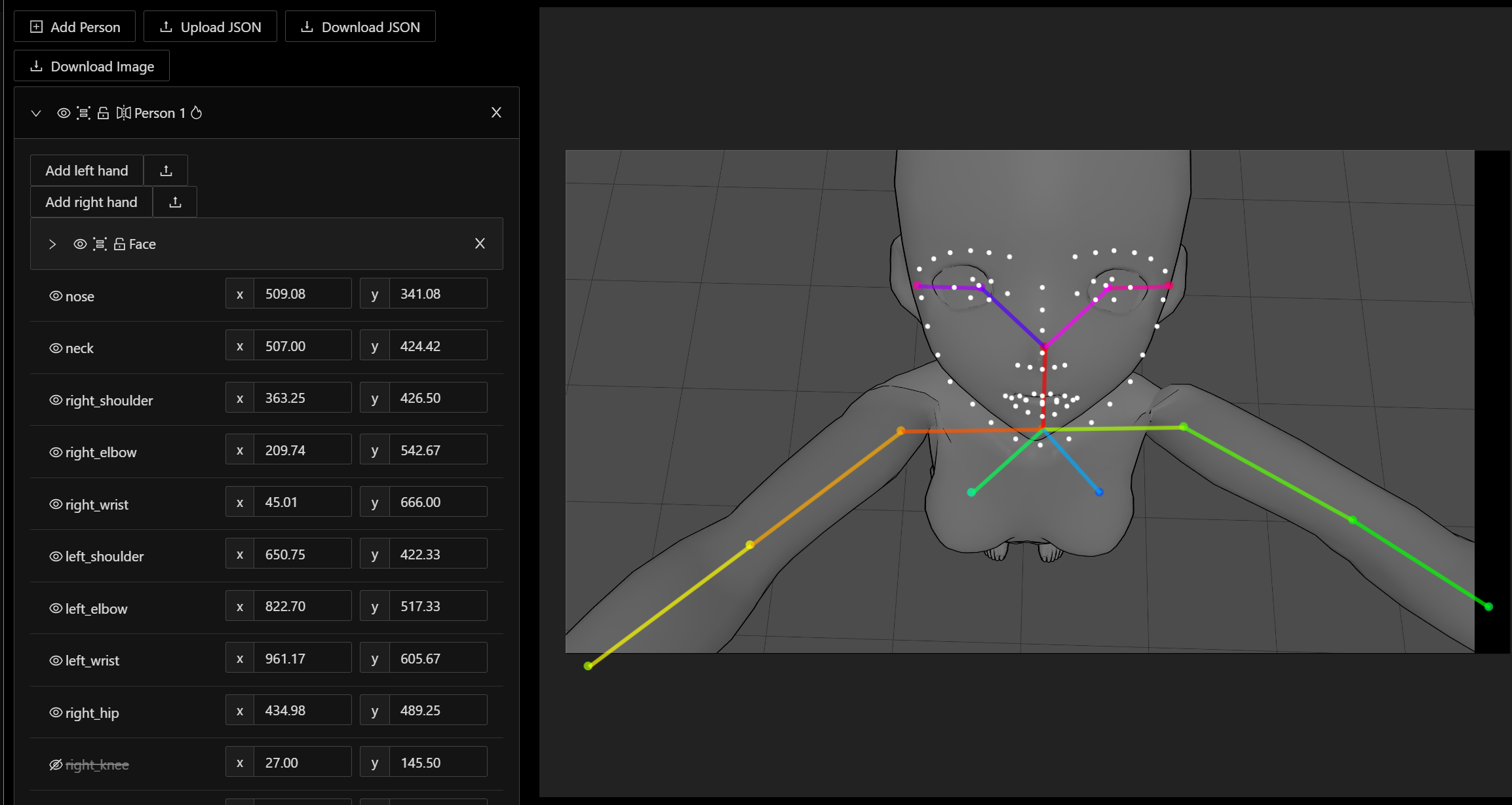
You can see why a lot of detail in the marionette isn't needed; the control net model can be simple - or complex if you need it. Hands, and the face outline, eyes, nose and mouth can become very detailed, but for this image, with this workflow, not including the hands, and it actually works a bit better if the initial image created by SD has a neutral expression as I usually replace it using the image2image inpaint method.
After SD renders the new image with ControlNET overriding the character prompts you get an image like this:

So, pretty close to the original image the prompt generated, but the arms and head position are exactly where I wanted them. There are some artifacts that need to be cleaned up (the braids are out of control, the eye color is wrong, etc...) - but normally there are 2 additional rounds of SD img2img and SD img2img inpaint in my typical workflow to go from initial concept image to final image for the game.
So, why not use ControlNET for all images in the game?
- It takes a lot longer to set up the concept image - need to find or create the input image, then pre-process it and correct the wire model.
- It's slower to render; once controlNET hooks into the SD rendering stream it takes over an hour to generate a single image.
- It still isn't perfect, the wire model doesn't always get interpreted correctly.
- Lose all spontaneity - the SD token interpreter creates lots of happy accidents that lead to stunning or breathtaking images - controlNET really suppresses this.
Taken on average, the amount of time it takes to generate an image from prompt driven SD interpretation is about a tenth of what it takes going the ControlNET route. Therefore, I consider it a crutch to use when I can't get the correct tokens to realize the image I need, and plan to use it sparingly in this project.
I hope you found this side-discussion interesting, please comment if you're interested in other posts of this type while I continue losing sleep to deliver Workin' Out.
Regards,
-Insomniac
Leave a comment
Log in with itch.io to leave a comment.